# 架构介绍
| Hostname | IP | 用户 |
|---|---|---|
| controller (跳板机) | 222.200.180.102 | openstack |
| cpf-1 (虚拟机) | 10.10.3.183 | ubuntu |
| cpf-2 (虚拟机) | 10.10.1.96 | ubuntu |
| cpf-3 (虚拟机) | 10.10.3.222 | ubuntu |
| cpf-4 (虚拟机) | 10.10.0.176 | ubuntu |
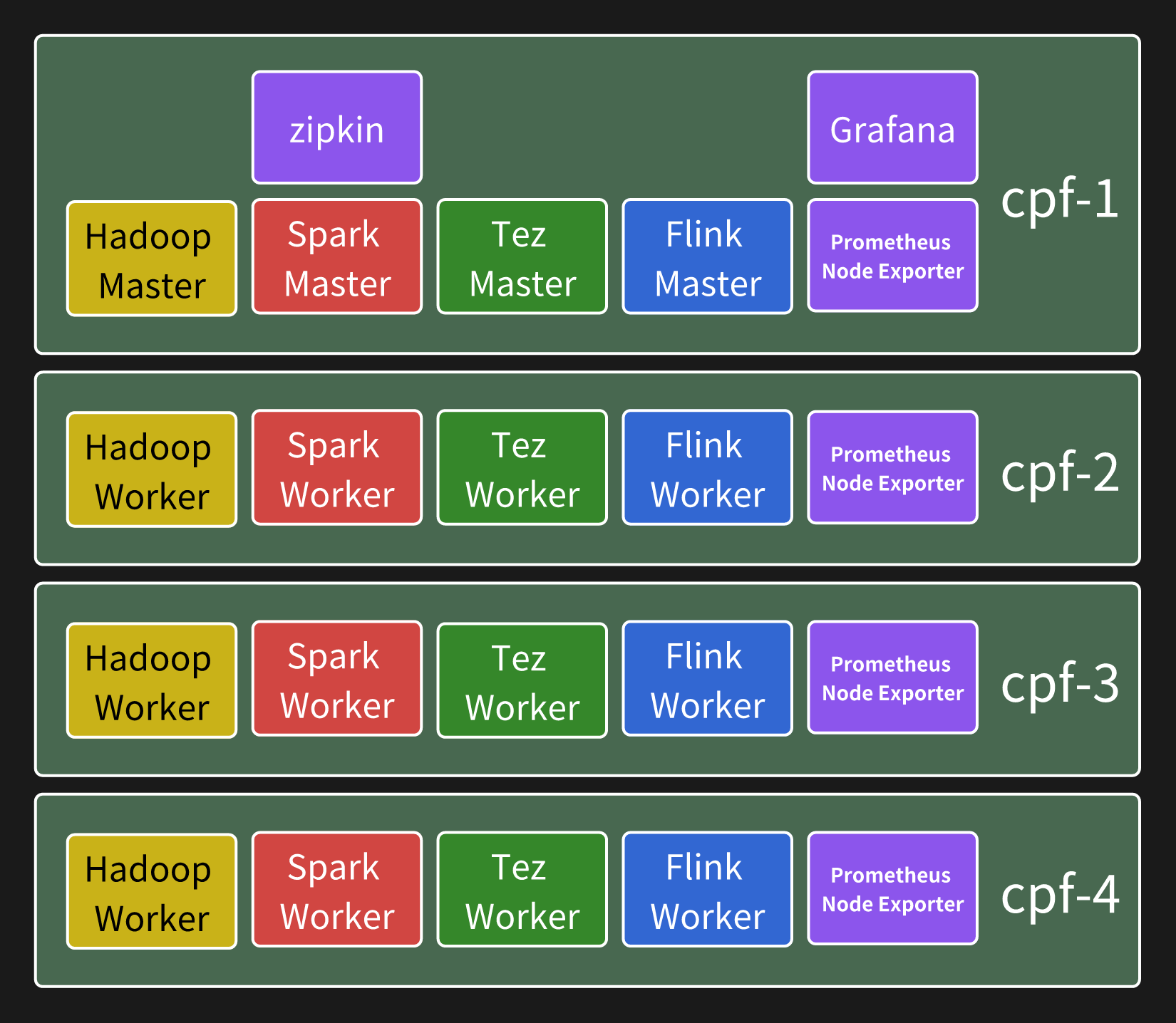
本文在内网环境中的 4 个节点上部署一套包含 Hadoop、Spark、Tez、Flink 的环境,文中提到的跳板机和节点如上所示。
最终搭建起的架构如图所示:(忽略其中的 zipkin, promethus, grafana 本文暂不讨论)
# Hadoop
安装 兼容版本的 Java,我这里使用 Ubuntu 24.02,直接使用 apt 安装 Java 8 :
sudo apt install openjdk-8-jre |
通过 which java ,查看软链接,找到 Java 的实际安装目录,在我这里为 /usr/lib/jvm/java-8-openjdk-amd64 。
下载 Hadoop,我这里选择下载 hadoop-stable 的为 hadoop-3.4.1 。直接 wget 下载然后 tar -zxvf 解压。我下载时国内网速太慢,挂了梯子下载然后 scp 分发。
在所有节点上执行如下:
sudo tar xzf hadoop-3.4.1.tar.gz -C /opt | |
sudo ln -s /opt/hadoop-3.4.1/ /opt/hadoop | |
sudo chown -R ubuntu:ubuntu /opt/hadoop | |
sudo chown -R ubuntu:ubuntu /opt/hadoop-3.4.1 | |
sudo mkdir data | |
sudo mkdir /data/hadoop | |
sudo chown -R ubuntu:ubuntu /data/hadoop | |
mkdir /data/hadoop/data | |
mkdir /data/hadoop/name | |
mkdir /data/hadoop/pid | |
mkdir /data/hadoop/tmp |
然后,在 /opt/hadoop/etc/hadoop 目录下,编辑配置文件:
core-site.xml :
# Add these elements: | |
## Do not forget to change the tmp directory | |
<property> | |
<name>fs.defaultFS</name> | |
<value>hdfs://{master}:9000</value> | |
</property> | |
<property> | |
<name>hadoop.tmp.dir</name> | |
<value>/data/hadoop/tmp</value> | |
</property> |
hadoop-env.sh :
# Add these commands: | |
## Do not forget to change the PID directory | |
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 | |
export HADOOP_PID_DIR=/data/hadoop/pid |
hdfs-site.xml :
# Add these elements: | |
## dfs.replication property specifies replication factor, you may want to change it. I prefer replication factor of two for small clusters. | |
## Do not forget to change the data directory | |
## Do not forget to change the name directory | |
<property> | |
<name>dfs.namenode.http-address</name> | |
<value>{master}:9001</value> | |
</property> | |
<property> | |
<name>dfs.namenode.secondary.http-address</name> | |
<value>{master}:9002</value> | |
</property> | |
<property> | |
<name>dfs.webhdfs.enabled</name> | |
<value>true</value> | |
</property> | |
<property> | |
<name>dfs.replication</name> | |
<value>2</value> | |
</property> | |
<property> | |
<name>dfs.data.dir</name> | |
<value>/data/hadoop/data</value> | |
</property> | |
<property> | |
<name>dfs.name.dir</name> | |
<value>/data/hadoop/name</value> | |
</property> | |
<property> | |
<name>dfs.permission</name> | |
<value>false</value> | |
</property> |
mapred-site.xml :
# Add these elements: | |
<property> | |
<name>mapreduce.framework.name</name> | |
<value>yarn</value> | |
</property> | |
<property> | |
<name>mapreduce.application.classpath</name> | |
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value> | |
</property> | |
<property> | |
<name>mapred.job.tracker</name> | |
<value>{master}:54311</value> | |
</property> | |
# The host and port that the MapReduce job tracker runs at. If "local", then jobs are run in-process as a single map and reduce task. |
workers :
# Add the names of all workers | |
cpf-2 | |
cpf-3 | |
cpf-4 |
yarn-site.xml :
# Add these lines | |
## You may want to change the max-disk-utilization-per-disk-percentage. | |
## Notice that the value of "yarn.nodemanager.hostname" property is {worker}. We leave it for now, and will change it later | |
<property> | |
<name>yarn.nodemanager.aux-services</name> | |
<value>mapreduce_shuffle</value> | |
</property> | |
<property> | |
<name>yarn.nodemanager.env-whitelist</name> | |
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> | |
</property> | |
<property> | |
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name> | |
<value>95</value> | |
</property> | |
<property> | |
<name>yarn.resourcemanager.hostname</name> | |
<value>{master}</value> | |
</property> | |
<property> | |
<name>yarn.nodemanager.hostname</name> | |
<value>{worker}</value> | |
</property> |
通过 sudo vim /etc/profile.d/apache-01-hadoop.sh 编辑一个 Hadoop 相关环境变量的配置文件,这个文件命名是为了在后续加载 Spark、Tez 环境变量的配置文件之前完成加载,因为后者依赖于这里的一些环境变量。
# Java | |
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 | |
# Haddop & YARN | |
export PDSH_RCMD_TYPE=ssh | |
export HADOOP_HOME=/opt/hadoop | |
export HADOOP_CONF_DIR=/opt/hadoop/etc/hadoop | |
export HADOOP_MAPRED_HOME=/opt/hadoop | |
export HADOOP_COMMON_HOME=/opt/hadoop | |
export HADOOP_HDFS_HOME=/opt/hadoop | |
export HADOOP_YARN_HOME=/opt/hadoop | |
export PATH=$HADOOP_HOME/bin:$PATH | |
export HDFS_NAMENODE_USER="ubuntu" | |
export HDFS_DATANODE_USER="ubuntu" | |
export HDFS_SECONDARYNAMENODE_USER="ubuntu" | |
export YARN_RESOURCEMANAGER_USER="ubuntu" | |
export YARN_NODEMANAGER_USER="ubuntu" | |
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native |
然后就可以启动 hadoop 试试看了,常用操作如下:
# 格式化 (清除) hdfs | |
hadoop namenode -format | |
# 启动 hdfs 和 yarn 集群 | |
/opt/hadoop/sbin/start-dfs.sh | |
/opt/hadoop/sbin/start-yarn.sh | |
# 停止 hdfs 和 yarn 集群 | |
/opt/hadoop/sbin/stop-yarn.sh | |
/opt/hadoop/sbin/stop-dfs.sh |
万一误操作导致 hdfs 文件系统爆了,在所有节点上执行如下脚本:
#!/bin/bash | |
rm -rf /data/hadoop/data | |
rm -rf /data/hadoop/name | |
rm -rf /data/hadoop/pid | |
rm -rf /data/hadoop/tmp | |
mkdir -p /data/hadoop/data | |
mkdir -p /data/hadoop/name | |
mkdir -p /data/hadoop/pid | |
mkdir -p /data/hadoop/tmp |
# Spark
同样首先还是在所有节点上安装二进制程序到 /opt 下:
sudo tar xzf spark-3.4.4-bin-hadoop3.tgz -C /opt | |
sudo ln -s /opt/spark-3.4.4-bin-hadoop3/ /opt/spark | |
sudo chown -R ubuntu:ubuntu /opt/spark | |
sudo chown -R ubuntu:ubuntu /opt/spark-3.4.4-bin-hadoop3 |
然后将 hadoop 的相关配置文件复制到 spark 的配置目录下:
cp /opt/hadoop/etc/hadoop/core-site.xml /opt/spark/conf/ | |
cp /opt/hadoop/etc/hadoop/hdfs-site.xml /opt/spark/conf/ | |
cp /opt/hadoop/etc/hadoop/yarn-site.xml /opt/spark/conf/ |
然后,在 /opt/spark/conf 目录下,编辑配置文件:
workers :
# 写入 worker 节点 hostname (当然不一定要复制模板) | |
cpf-2 | |
cpf-3 | |
cpf-4 |
cp spark-env.sh.template spark-env.sh 后在 spark-env.sh 增加如下内容 :
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 | |
export SPARK_HOME=/opt/spark | |
export SPARK_CONF_DIR=$SPARK_HOME/conf | |
export HADOOP_HOME=/opt/hadoop | |
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop | |
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop | |
export SPARK_WORKER_DIR=/tmp/spark/work |
cp log4j2.properties.template log4j2.properties 使用默认配置即可。
sudo vim /etc/profile.d/apache-02-spark.sh 配置 Spark 相关环境变量:
export SPARK_HOME=/opt/spark | |
export SPARK_CONF_DIR=$SPARK_HOME/conf | |
export PATH=$SPARK_HOME/bin:$PATH |
最后上传 Spark 相关 jar 文件到 HDFS:
hdfs dfs -mkdir -p /user/spark/share/lib | |
hadoop fs -put /opt/spark/jars/* /user/spark/share/lib/ |
# Tez
sudo tar xzf apache-tez-0.10.5-bin.tar.gz -C /opt | |
sudo ln -s /opt/apache-tez-0.10.5-bin/ /opt/tez | |
sudo chown -R ubuntu:ubuntu /opt/tez | |
sudo chown -R ubuntu:ubuntu /opt/apache-tez-0.10.5-bin |
将解压出来的 share/tez.tar.gz 上传到 hdfs 中:
hadoop fs -mkdir -p /apps/tez | |
hadoop fs -copyFromLocal /opt/tez/share/tez.tar.gz /apps/tez/ |
准备一个配置文件 tez-site.xml ,在 /opt/tez/conf 目录中将有自动生成的配置文件模板,所以我们的配置文件也放在这里。这里仅配置一项即可:
<configuration> | |
<property> | |
<name>tez.lib.uris</name> | |
<value>${fs.defaultFS}/apps/tez/tez.tar.gz</value> | |
</property> | |
</configuration> |
sudo vim /etc/profile.d/apache-03-tez.sh 配置 Spark 相关环境变量:
export TEZ_HOME=/opt/tez | |
export TEZ_CONF_DIR=${TEZ_HOME}/conf | |
export TEZ_JARS=${TEZ_HOME} | |
export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${TEZ_CONF_DIR}:${TEZ_JARS}/*:${TEZ_JARS}/lib/* |
# Flink
Flink on YARN 支持如下几种模式:
- Session 模式,先将 Flink 集群作为一个作业提交给 YARN 来启动集群,然后再提交作业,且后续提交的作业共享 Flink 集群的资源。
- Attached 模式,顾名思义前台运行;
- Dettached 模式,顾名思义后台运行;
- Application 模式,直接提交作业。提交后在 YARN 上启动一个 Flink 集群,应用程序 jar 的
main()方法将在 YARN 中的 JobManager 上执行。应用程序一完成,集群就会关闭。
接下来部署一个 Dettached Session 模式的 Flink 集群,这将同时提供一个 Web UI 供提交监控 Flink 作业。
首先还是在所有节点上安装二进制程序到 /opt 下:
sudo tar xzf flink-2.0.0.tar.gz -C /opt | |
sudo ln -s /opt/flink-2.0.0/ /opt/flink | |
sudo chown -R ubuntu:ubuntu /opt/flink | |
sudo chown -R ubuntu:ubuntu /opt/flink-2.0.0 |
然后修改配置文件 /opt/flink/conf/config.yaml ,指定 Flink 版本所兼容的 Java 版本,例如这里 Flink 2.0.0 需要 Java 17+ 版本,我将其指定为 apt 安装的 Java 17 安装路径:
env: | |
java: | |
home: /usr/lib/jvm/java-17-openjdk-amd64 | |
# | |
# ...... | |
# | |
rest: | |
port: xxxxx # 绑定 Web UI 到指定端口 |
上面配置修改了 rest.port 绑定 Web UI 端口,因为默认的 8081 端口已经被 Hadoop 和 YARN 占用了,避免每次启动都是随机端口。尽管如此,还是无法绑定到指定 address 上,因为提交 Flink 集群后,前端分配到哪个节点是不确定的,只能在启动后确定。
但是,我们的 Hadoop 和 YARN 依然依赖于 Java 8 所以当前环境变量 JAVA_HOME 指向的 Java 路径是 Java 8 的,并且 Flink 也依赖于这个环境变量!所以即使加了上面的配置启动集群时还是会有 Java 版本不兼容的报错。所以只好启动的时候指定一个高版本 Java 路径:
JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 ./bin/yarn-session.sh -d |
然后会输出 Web UI 的访问方式,以及 Flink 集群的 application id 用于停止集群。当然,YARN 面板上随时可以查到这个 Flink 集群的 application id,所以并不一定需要记下它。
当然,停止集群的时候也要指定 Java 路径:
echo "stop" | JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 ./bin/yarn-session.sh -id <application_id> |
但是接下来还有可能遇到一个问题导致提交的作业永远无法顺利执行,就是资源限制问题。和 Spark 和 Tez 不太一样,Flink 需要一个作业作为 Flink 集群,若我们使用同一个用户启动 Flink 集群,再提交其他非 Flink 作业时可能会发现作业卡住永远没有进展,是因为当前用户 AM 资源上限被 Flink 集群这个作业占完了。似乎能修改配置解决,有比较好的解决方案了后续再补上...
# 访问内网环境
在 ~/.ssh/config 中添加如下配置:
Host hadoop-tunnel
HostName 222.200.180.102
User openstack
# HDFS Web UI (namenode)
LocalForward 9870 10.10.3.183:9870
# HDFS Web UI (secondary namenode)
LocalForward 9868 10.10.3.183:9868
# YARN Web UI
LocalForward 8088 10.10.3.183:8088
LocalForward 8042 10.10.1.96:8042
LocalForward 8043 10.10.3.222:8042
LocalForward 8044 10.10.0.176:8042
# zipkin Web UI
LocalForward 9411 10.10.3.183:9411
# JobHistory Web UI
LocalForward 19888 10.10.3.183:19888
# Promethues Web UI
LocalForward 9090 10.10.3.183:9090
# Node_Exporter Web UI
LocalForward 9100 10.10.3.183:9100
LocalForward 9200 10.10.1.96:9100
LocalForward 9300 10.10.3.222:9100
LocalForward 9400 10.10.0.176:9100
# Grafana Web UI 监控可视化
LocalForward 3000 10.10.3.183:3000
Host cpf-1
HostName 10.10.3.183
User ubuntu
ProxyCommand ssh -W %h:%p hadoop-tunnel
Host cpf-2
HostName 10.10.1.96
User ubuntu
ProxyCommand ssh -W %h:%p hadoop-tunnel
Host cpf-3
HostName 10.10.3.222
User ubuntu
ProxyCommand ssh -W %h:%p hadoop-tunnel
Host cpf-4
HostName 10.10.0.176
User ubuntu
ProxyCommand ssh -W %h:%p hadoop-tunnel
基于上述配置:
ssh -N hadoop-tunnel # 会挂着转发全部 Web 应用 | |
ssh hadoop-tunnel # 登录跳板机,顺便转发全部 Web 应用 | |
ssh cpf-1 # 登录虚拟机 |
# 提交任务
除了 Flink 都需要连接到虚拟机上提交。
# Spark
需要通过 spark-submit 来提交。
由于是 Spark on YARN 的部署方式,提交的任务中,SparkSession 需要增加一项配置 .config("spark.hadoop.fs.defaultFS", "hdfs://cpf-1:9000") 来指定使用 YARN 和 hadoop,并且在提交时指定 --master yarn --deploy-mode cluster 。
spark-submit | |
--master yarn \ | |
--deploy-mode cluster \ | |
xxxApp |
使用 Spot 追踪,假设追踪后端为 zipkin 并且部署在 http://cpf-1:9411,需要增加:
spark-submit | |
--jars spot-complete-3.5_2.12-0.1.1.jar \ | |
--conf spark.extraListeners=com.xebia.data.spot.TelemetrySparkListener \ | |
--conf spark.otel.traces.exporter=zipkin \ | |
--conf spark.otel.exporter.zipkin.endpoint=http://cpf-1:9411/api/v2/spans \ | |
xxxApp |
这里的 spot-complete-3.5_2.12-x.x.x.jar 从 这个 fork 的 CI (build) 下载,因为原项目仓库依赖缺少 opentelemetry-exporter-zipkin 会导致用 zipkin 测试失败。
python 测试为例如下:
from pyspark.sql import SparkSession | |
spark = SparkSession\ | |
.builder\ | |
.config("spark.hadoop.fs.defaultFS", "hdfs://cpf-1:9000")\ | |
.appName("test01")\ | |
.getOrCreate() | |
def get_python_version(_): | |
import sys | |
print("Python version:", sys.version) | |
def get_packages(_): | |
import pkg_resources | |
print({pkg.key: pkg.version for pkg in pkg_resources.working_set}) | |
# Driver 端的 Python 版本 | |
get_python_version(114) | |
# Executor 端的 Python 版本 | |
spark.sparkContext.parallelize([1], 1).map(get_python_version).collect() | |
# 列出所有 Driver 端的包名 | |
get_packages(514) | |
# 列出所有 Executor 端的包名 | |
spark.sparkContext.parallelize([1], 1).map(get_packages).collect() | |
spark.stop() |
提交测试并追踪:
spark-submit \ | |
--master yarn \ | |
--deploy-mode cluster \ | |
--jars spot-complete-3.5_2.12-0.1.1.jar \ | |
--conf spark.extraListeners=com.xebia.data.spot.TelemetrySparkListener \ | |
--conf spark.otel.traces.exporter=zipkin \ | |
--conf spark.otel.exporter.zipkin.endpoint=http://cpf-1:9411/api/v2/spans \ | |
test.py |
# Flink
可以直接通过 Web UI 提交,也可以登陆虚拟机通过指令提交,只是提交时必须指定 JAVA_HOME (默认的 JAVA_HOME 是给 hadoop 和 yarn 用的 java 8):
JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 \ | |
/opt/flink/bin/flink run \ | |
/opt/flink/examples/streaming/TopSpeedWindowing.jar |
# Tez
虚拟机上通过指令按照普通的 MapReduce 任务提交即可,例如:
hadoop \ | |
jar tez-examples-0.10.5.jar \ | |
orderedwordcount \ | |
/tmp/test/wordcount-input \ | |
/tmp/test/wordcount-output |